Trie Exercise 1
前缀树 ,又称 字典树 ,是 N 叉树 的特殊形式
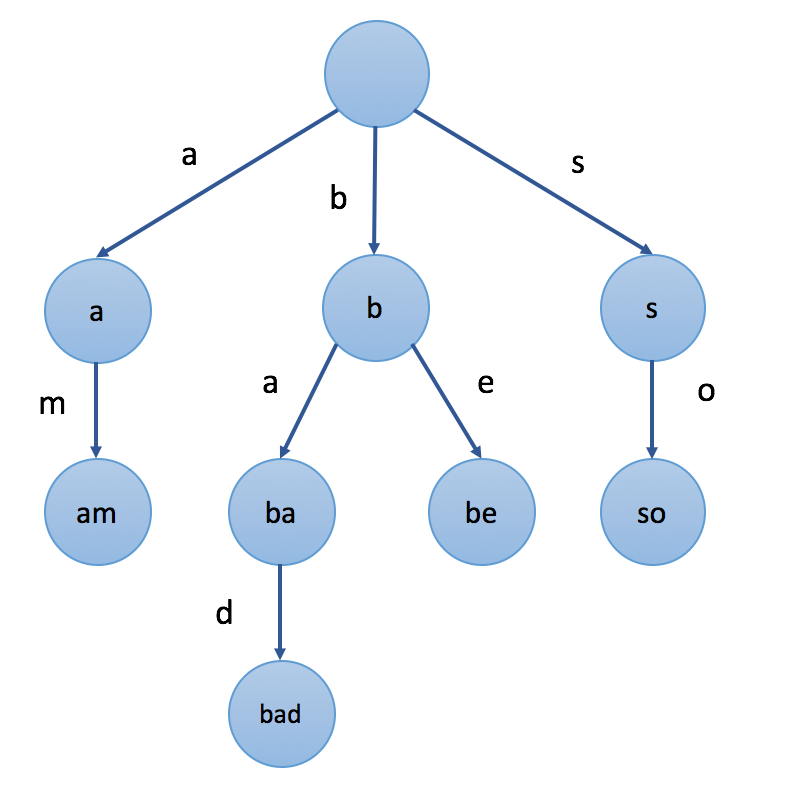
前缀树的插入和搜索
实际应用 I
前缀树广泛应用于 存储 字符串和 检索 关键字,特别是和 前缀 相关的关键字。
自动补全

一个简单的实现自动补全的方法是在前缀树中存储ngram,并根据词频进行搜索推荐。请仔细思考,什么是解决这个问题的理想的节点结构。
拼写检查(添加与搜索单词 - 数据结构设计)
在前缀树中找到具有相同前缀的单词很容易。但是怎么找到相似的单词呢?你可能需要运用一些搜索算法来解决这个问题。
实际应用 II
在前一章节中,我们练习了几道经典的的前缀树问题。但是,前缀树的实际应用并不只是那么简单。
- 加速深度优先搜索
- 有时,我们会用前缀树来加速深度优先搜索。特别是当我们使用深度优先搜索解决文字游戏类问题的时候。 我们在文章后面为你提供习题:单词搜索 II 。请先尝试深度优先算法,再使用前缀树进行优化。
- 存储其他数据类型
- 我们通常会使用前缀树来存储字符串,但并非总是如此。 数组中两个数的最大异或值 是一道很有意思的问题。还有一些其他应用,例如 IP 路由(最长前缀匹配)。
练习:
208. Implement Trie (Prefix Tree)
难度中等1162
A trie (pronounced as “try”) or prefix tree is a tree data structure used to efficiently store and retrieve keys in a dataset of strings. There are various applications of this data structure, such as autocomplete and spellchecker.
Implement the Trie class:
Trie()Initializes the trie object.void insert(String word)Inserts the stringwordinto the trie.boolean search(String word)Returnstrueif the stringwordis in the trie (i.e., was inserted before), andfalseotherwise.boolean startsWith(String prefix)Returnstrueif there is a previously inserted stringwordthat has the prefixprefix, andfalseotherwise.
Example 1:
Input
["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
[[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
Output
[null, null, true, false, true, null, true]
Explanation
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // return True
trie.search("app"); // return False
trie.startsWith("app"); // return True
trie.insert("app");
trie.search("app"); // return True
Constraints:
1 <= word.length, prefix.length <= 2000wordandprefixconsist only of lowercase English letters.- At most
3 * 104calls in total will be made toinsert,search, andstartsWith
思路:
- 这道题就是如何实现字典树
- 首先是一个指针数组
children,children[0]代表’a’, children[25] reflects ‘z’ -
boolean attribute
is_end, determine whether it is the end - Insert
- this children[i] already exists, point go to next
- this children[i] doesn’t exist, create it, go to next
- repeat until we find the end, and let this children[i] is_end = 1
- search_prefix
- this children[i] already exists, point go to next
- this children[i] doesn’t exist, return None
- repeat until we return None or we find the end
- search
- node can be find in serach_prefix and node.is_end is 1
- startsWith
- just use search_prefix
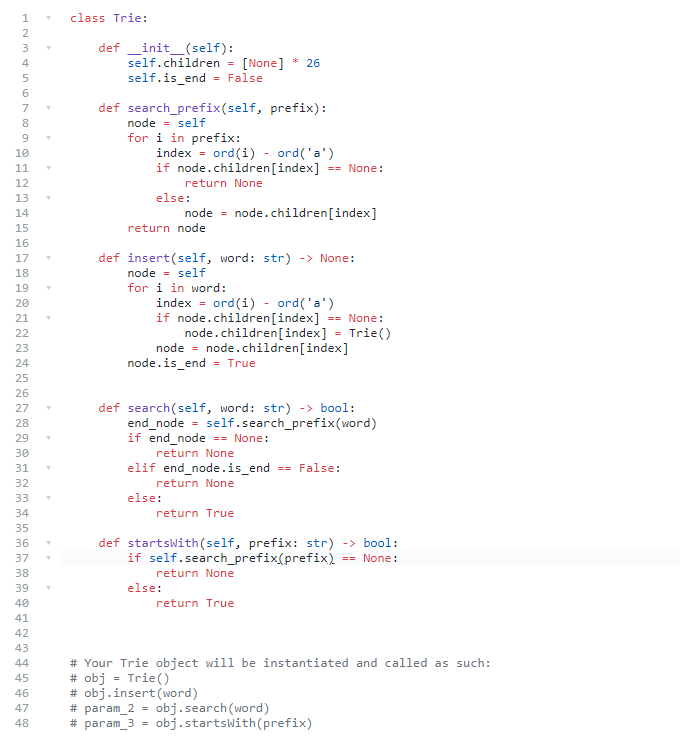
代码:
677. 键值映射
难度中等203
设计一个 map ,满足以下几点:
- 字符串表示键,整数表示值
- 返回具有前缀等于给定字符串的键的值的总和
实现一个 MapSum 类:
MapSum()初始化MapSum对象void insert(String key, int val)插入key-val键值对,字符串表示键key,整数表示值val。如果键key已经存在,那么原来的键值对key-value将被替代成新的键值对。int sum(string prefix)返回所有以该前缀prefix开头的键key的值的总和。
示例 1:
输入:
["MapSum", "insert", "sum", "insert", "sum"]
[[], ["apple", 3], ["ap"], ["app", 2], ["ap"]]
输出:
[null, null, 3, null, 5]
解释:
MapSum mapSum = new MapSum();
mapSum.insert("apple", 3);
mapSum.sum("ap"); // 返回 3 (apple = 3)
mapSum.insert("app", 2);
mapSum.sum("ap"); // 返回 5 (apple + app = 3 + 2 = 5)
提示:
1 <= key.length, prefix.length <= 50key和prefix仅由小写英文字母组成1 <= val <= 1000- 最多调用
50次insert和sum
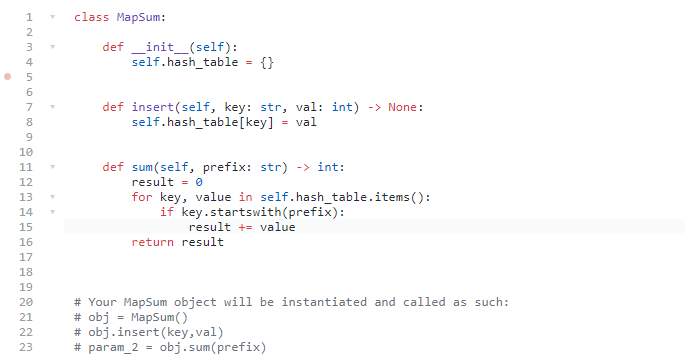
思路:
- Of course we can use brute force, we can store all keys and values in a hash table
- When we need to search prefix, we can search every key and value
- if the prefix in the key, we can add its value to the result
- 注意用self.hash_table.items(), 这样产生的才是键值对,用enumerate产生的是从0开始的index
- Python 对于str类型提供了一个.startswith()来判断string之间的1包含关系
- Time Complexity: N is num of keys, M is the length of the longest key
- insert is O(1), sum is O(NM)
-
Space Complexity: O(MN)
- However, since we are dealing with prefixes, we can use Trie to solve this problem. Trie is a natural data structure to approach this problem
- 对于insert,



648. 单词替换
难度中等166
在英语中,我们有一个叫做 词根(root) 的概念,可以词根后面添加其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典 dictionary 和一个用空格分隔单词形成的句子 sentence。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
示例 1:
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例 2:
输入:dictionary = ["a","b","c"], sentence = "aadsfasf absbs bbab cadsfafs"
输出:"a a b c"
提示:
1 <= dictionary.length <= 10001 <= dictionary[i].length <= 100dictionary[i]仅由小写字母组成。1 <= sentence.length <= 10^6sentence仅由小写字母和空格组成。sentence中单词的总量在范围[1, 1000]内。sentence中每个单词的长度在范围[1, 1000]内。sentence中单词之间由一个空格隔开。sentence没有前导或尾随空格。
思路:
- 使用map()来进行函数的迭代。
- 最简单的方法是对于每个单词,用sentence.split()来去除空格并且提取
- 时间复杂度:然后对于每个单词都进行一次搜索看看需不需要replace。对于长度为xi的单词,需要xi ^ 2检查,一共是O(N*xi^2)。但是没太想明白
- 空间复杂度:我认为map的时候可能也要用空间,姑且认为是O(N)
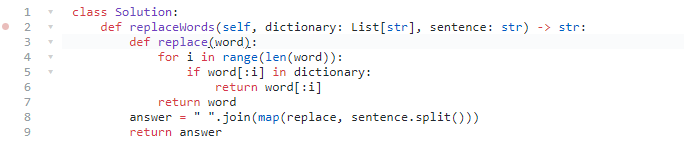
- 更好的办法是把所有的词根都放在前缀树上,在树上查找每个单词的最短词根
-
这样空间时间都是O(N)
- 完整实现的,一点不快,而且空间消耗更大,不清楚为什么说是O(N)

- 两个for的是最快的

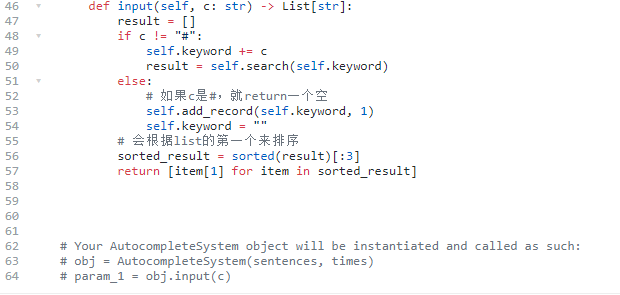
642. 设计搜索自动补全系统
难度困难122
为搜索引擎设计一个搜索自动补全系统。用户会输入一条语句(最少包含一个字母,以特殊字符 '#' 结尾)。
给定一个字符串数组 sentences 和一个整数数组 times ,长度都为 n ,其中 sentences[i] 是之前输入的句子, times[i] 是该句子输入的相应次数。对于除 ‘#’ 以外的每个输入字符,返回前 3 个历史热门句子,这些句子的前缀与已经输入的句子的部分相同。
下面是详细规则:
- 一条句子的热度定义为历史上用户输入这个句子的总次数。
- 返回前
3的句子需要按照热度从高到低排序(第一个是最热门的)。如果有多条热度相同的句子,请按照 ASCII 码的顺序输出(ASCII 码越小排名越前)。 - 如果满足条件的句子个数少于
3,将它们全部输出。 - 如果输入了特殊字符,意味着句子结束了,请返回一个空集合。
实现 AutocompleteSystem 类:
-
AutocompleteSystem(String[] sentences, int[] times):使用数组sentences和times对对象进行初始化。 -
List<String> input(char c)表示用户输入了字符
c。
- 如果
c == '#',则返回空数组[],并将输入的语句存储在系统中。 - 返回前
3个历史热门句子,这些句子的前缀与已经输入的句子的部分相同。如果少于3个匹配项,则全部返回。
- 如果
示例 1:
输入
["AutocompleteSystem", "input", "input", "input", "input"]
[[["i love you", "island", "iroman", "i love leetcode"], [5, 3, 2, 2]], ["i"], [" "], ["a"], ["#"]]
输出
[null, ["i love you", "island", "i love leetcode"], ["i love you", "i love leetcode"], [], []]
解释
AutocompleteSystem obj = new AutocompleteSystem(["i love you", "island", "iroman", "i love leetcode"], [5, 3, 2, 2]);
obj.input("i"); // return ["i love you", "island", "i love leetcode"]. There are four sentences that have prefix "i". Among them, "ironman" and "i love leetcode" have same hot degree. Since ' ' has ASCII code 32 and 'r' has ASCII code 114, "i love leetcode" should be in front of "ironman". Also we only need to output top 3 hot sentences, so "ironman" will be ignored.
obj.input(" "); // return ["i love you", "i love leetcode"]. There are only two sentences that have prefix "i ".
obj.input("a"); // return []. There are no sentences that have prefix "i a".
obj.input("#"); // return []. The user finished the input, the sentence "i a" should be saved as a historical sentence in system. And the following input will be counted as a new search.
提示:
n == sentences.lengthn == times.length1 <= n <= 1001 <= sentences[i].length <= 1001 <= times[i] <= 50c是小写英文字母,'#', 或空格' '- 每个被测试的句子将是一个以字符
'#'结尾的字符c序列。 - 每个被测试的句子的长度范围为
[1,200] - 每个输入句子中的单词用单个空格隔开。
input最多被调用5000次
思路:
- 首先对于字典树的构成,我们可以用dict()也可以用list
- 通常用dict()是担心列表存储的是数字,会很稀疏。但是字母就无所谓了
- 不过用list要用ord()来计算下标,使用dict不用,所以综合来看,还是dict更好
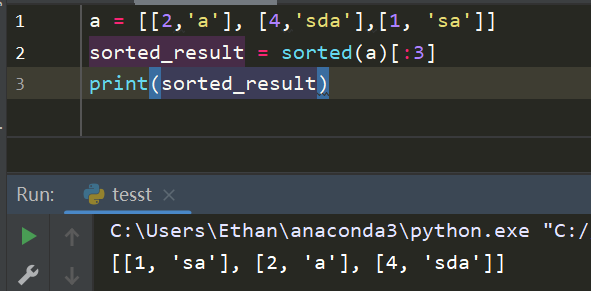
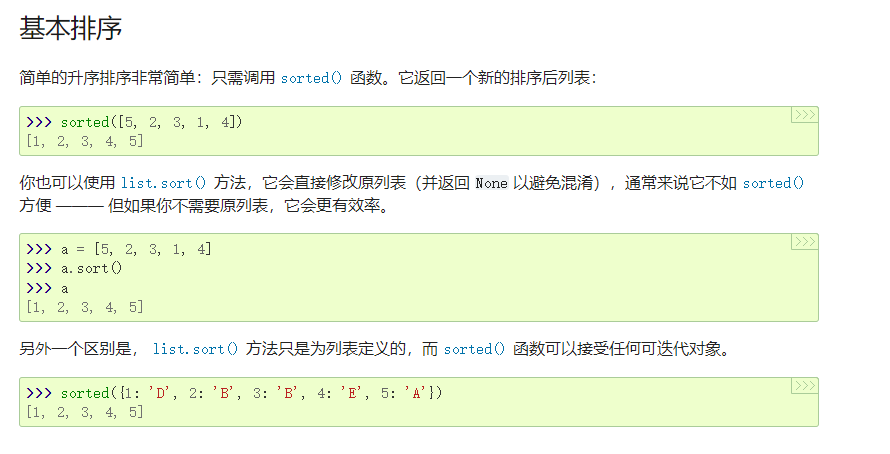
- 使用sorted而不是sort()
代码:
- 41行用set还是用list都一样

211. 添加与搜索单词 - 数据结构设计
难度中等422
请你设计一个数据结构,支持 添加新单词 和 查找字符串是否与任何先前添加的字符串匹配 。
实现词典类 WordDictionary :
WordDictionary()初始化词典对象void addWord(word)将word添加到数据结构中,之后可以对它进行匹配bool search(word)如果数据结构中存在字符串与word匹配,则返回true;否则,返回false。word中可能包含一些'.',每个.都可以表示任何一个字母。
示例:
输入:
["WordDictionary","addWord","addWord","addWord","search","search","search","search"]
[[],["bad"],["dad"],["mad"],["pad"],["bad"],[".ad"],["b.."]]
输出:
[null,null,null,null,false,true,true,true]
解释:
WordDictionary wordDictionary = new WordDictionary();
wordDictionary.addWord("bad");
wordDictionary.addWord("dad");
wordDictionary.addWord("mad");
wordDictionary.search("pad"); // 返回 False
wordDictionary.search("bad"); // 返回 True
wordDictionary.search(".ad"); // 返回 True
wordDictionary.search("b.."); // 返回 True
提示:
1 <= word.length <= 25addWord中的word由小写英文字母组成search中的word由 ‘.’ 或小写英文字母组成- 最多调用
104次addWord和search
思路:
- 使用hash map会是很简单的
- Why Trie and not HashMap?
- This solution passes all leetcode test cases, and formally has O(MN) time complexity for the search, where M is a length of the word to find, and N*is the number of words. Although this solution is not efficient for the most important practical use cases:
- Finding all keys with a common prefix.
- Enumerating a dataset of strings in lexicographical order.按照词典顺序列举字符串数据集。
- Scaling for the large datasets.大型数据集的缩放 Once the hash table increases in size, there are a lot of hash collisions and the search time complexity could degrade to O(N^2⋅M), where Nis the number of the inserted keys.
- Trie could use less space compared to hashmap when storing many keys with the same prefix. In this case, using trie has only O(M⋅N) time complexity, where M is the key length, and N is the number of keys.
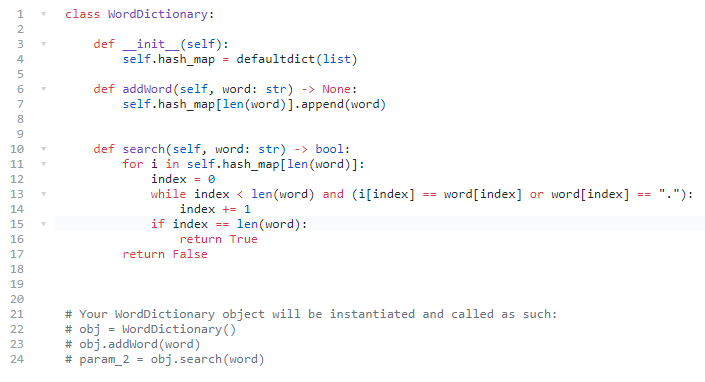
- 好,那么我们怎么用trie解决这个问题?
添加:
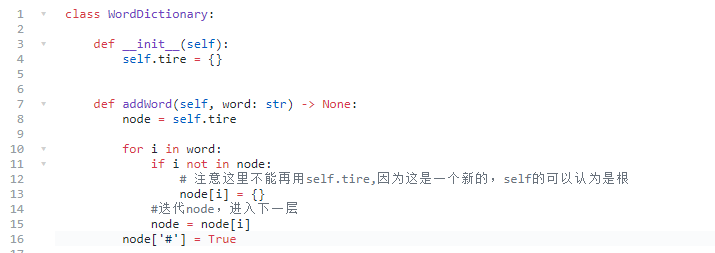
搜索:

425. 单词方块
难度困难77
给定一个单词集合 words (没有重复),找出并返回其中所有的 单词方块 。 words 中的同一个单词可以被 多次 使用。你可以按 任意顺序 返回答案。
一个单词序列形成了一个有效的 单词方块 的意思是指从第 k 行和第 k 列 0 <= k < max(numRows, numColumns) 来看都是相同的字符串。
- 例如,单词序列
["ball","area","lead","lady"]形成了一个单词方块,因为每个单词从水平方向看和从竖直方向看都是相同的。
示例 1:
输入:words = ["area","lead","wall","lady","ball"]
输出: [["ball","area","lead","lady"],
["wall","area","lead","lady"]]
解释:
输出包含两个单词方块,输出的顺序不重要,只需要保证每个单词方块内的单词顺序正确即可。
示例 2:
输入:words = ["abat","baba","atan","atal"]
输出:[["baba","abat","baba","atal"],
["baba","abat","baba","atan"]]
解释:
输出包含两个单词方块,输出的顺序不重要,只需要保证每个单词方块内的单词顺序正确即可。
提示:
1 <= words.length <= 10001 <= words[i].length <= 4words[i]长度相同words[i]只由小写英文字母组成words[i]都 各不相同
336. 回文对
难度困难305
给定一组 互不相同 的单词, 找出所有 不同 的索引对 (i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
示例 1:
输入:words = ["abcd","dcba","lls","s","sssll"]
输出:[[0,1],[1,0],[3,2],[2,4]]
解释:可拼接成的回文串为 ["dcbaabcd","abcddcba","slls","llssssll"]
示例 2:
输入:words = ["bat","tab","cat"]
输出:[[0,1],[1,0]]
解释:可拼接成的回文串为 ["battab","tabbat"]
示例 3:
输入:words = ["a",""]
输出:[[0,1],[1,0]]
提示:
1 <= words.length <= 50000 <= words[i].length <= 300words[i]由小写英文字母组成
139. 单词拆分
难度中等1578
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。请你判断是否可以利用字典中出现的单词拼接出 s 。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = "leetcode", wordDict = ["leet", "code"]
输出: true
解释: 返回 true 因为 "leetcode" 可以由 "leet" 和 "code" 拼接成。
示例 2:
输入: s = "applepenapple", wordDict = ["apple", "pen"]
输出: true
解释: 返回 true 因为 "applepenapple" 可以由 "apple" "pen" "apple" 拼接成。
注意,你可以重复使用字典中的单词。
示例 3:
输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"]
输出: false
提示:
1 <= s.length <= 3001 <= wordDict.length <= 10001 <= wordDict[i].length <= 20s和wordDict[i]仅有小写英文字母组成wordDict中的所有字符串 互不相同
140. 单词拆分 II
难度困难586
给定一个字符串 s 和一个字符串字典 wordDict ,在字符串 s 中增加空格来构建一个句子,使得句子中所有的单词都在词典中。以任意顺序 返回所有这些可能的句子。
注意:词典中的同一个单词可能在分段中被重复使用多次。
示例 1:
输入:s = "catsanddog", wordDict = ["cat","cats","and","sand","dog"]
输出:["cats and dog","cat sand dog"]
示例 2:
输入:s = "pineapplepenapple", wordDict = ["apple","pen","applepen","pine","pineapple"]
输出:["pine apple pen apple","pineapple pen apple","pine applepen apple"]
解释: 注意你可以重复使用字典中的单词。
示例 3:
输入:s = "catsandog", wordDict = ["cats","dog","sand","and","cat"]
输出:[]
提示:
1 <= s.length <= 201 <= wordDict.length <= 10001 <= wordDict[i].length <= 10s和wordDict[i]仅有小写英文字母组成wordDict中所有字符串都 不同
472. 连接词
难度困难251
给你一个 不含重复 单词的字符串数组 words ,请你找出并返回 words 中的所有 连接词 。
连接词 定义为:一个完全由给定数组中的至少两个较短单词组成的字符串。
示例 1:
输入:words = ["cat","cats","catsdogcats","dog","dogcatsdog","hippopotamuses","rat","ratcatdogcat"]
输出:["catsdogcats","dogcatsdog","ratcatdogcat"]
解释:"catsdogcats" 由 "cats", "dog" 和 "cats" 组成;
"dogcatsdog" 由 "dog", "cats" 和 "dog" 组成;
"ratcatdogcat" 由 "rat", "cat", "dog" 和 "cat" 组成。
示例 2:
输入:words = ["cat","dog","catdog"]
输出:["catdog"]
提示:
1 <= words.length <= 1040 <= words[i].length <= 1000words[i]仅由小写字母组成0 <= sum(words[i].length) <= 105
212. 单词搜索 II
难度困难652
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
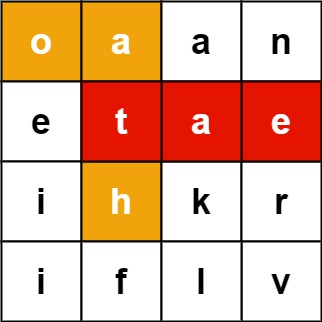
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
输出:["eat","oath"]
示例 2:

输入:board = [["a","b"],["c","d"]], words = ["abcb"]
输出:[]
提示:
m == board.lengthn == board[i].length1 <= m, n <= 12board[i][j]是一个小写英文字母1 <= words.length <= 3 * 1041 <= words[i].length <= 10words[i]由小写英文字母组成words中的所有字符串互不相同
588. Design In-Memory File System
难度困难77
Design a data structure that simulates an in-memory file system.
Implement the FileSystem class:
-
FileSystem()Initializes the object of the system. -
List<String> ls(String path)- If
pathis a file path, returns a list that only contains this file’s name. - If
pathis a directory path, returns the list of file and directory names in this directory.
The answer should in
lexicographic order
.
- If
-
void mkdir(String path)Makes a new directory according to the givenpath. The given directory path does not exist. If the middle directories in the path do not exist, you should create them as well. -
void addContentToFile(String filePath, String content)- If
filePathdoes not exist, creates that file containing givencontent. - If
filePathalready exists, appends the givencontentto original content.
- If
String readContentFromFile(String filePath)Returns the content in the file atfilePath.
Example 1:
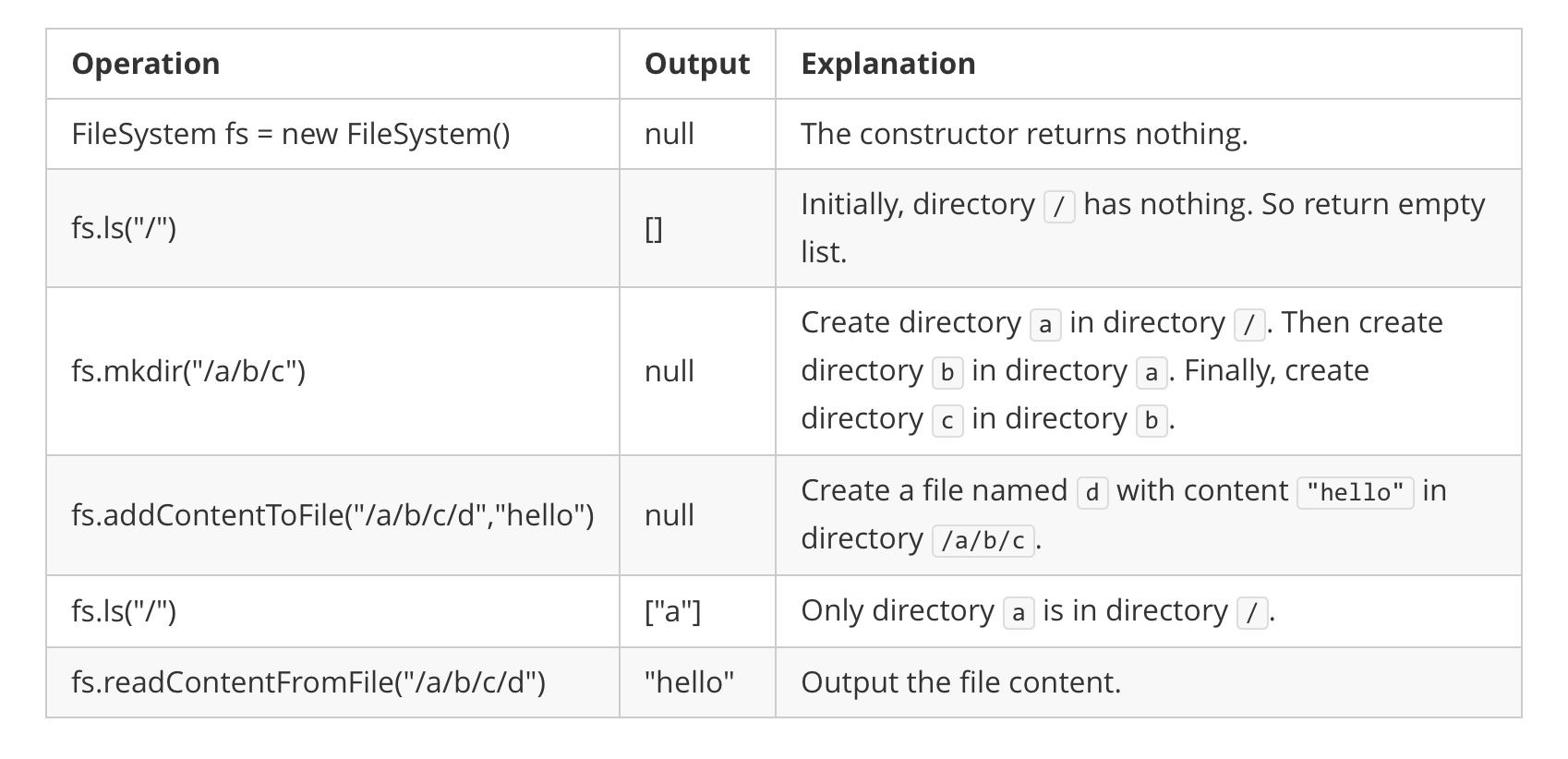
Input
["FileSystem", "ls", "mkdir", "addContentToFile", "ls", "readContentFromFile"]
[[], ["/"], ["/a/b/c"], ["/a/b/c/d", "hello"], ["/"], ["/a/b/c/d"]]
Output
[null, [], null, null, ["a"], "hello"]
Explanation
FileSystem fileSystem = new FileSystem();
fileSystem.ls("/"); // return []
fileSystem.mkdir("/a/b/c");
fileSystem.addContentToFile("/a/b/c/d", "hello");
fileSystem.ls("/"); // return ["a"]
fileSystem.readContentFromFile("/a/b/c/d"); // return "hello"
Constraints:
1 <= path.length, filePath.length <= 100pathandfilePathare absolute paths which begin with'/'and do not end with'/'except that the path is just"/".- You can assume that all directory names and file names only contain lowercase letters, and the same names will not exist in the same directory.
- You can assume that all operations will be passed valid parameters, and users will not attempt to retrieve file content or list a directory or file that does not exist.
1 <= content.length <= 50- At most
300calls will be made tols,mkdir,addContentToFile, andreadContentFromFile.
1268. 搜索推荐系统
难度中等115
给你一个产品数组 products 和一个字符串 searchWord ,products 数组中每个产品都是一个字符串。
请你设计一个推荐系统,在依次输入单词 searchWord 的每一个字母后,推荐 products 数组中前缀与 searchWord 相同的最多三个产品。如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个。
请你以二维列表的形式,返回在输入 searchWord 每个字母后相应的推荐产品的列表。
示例 1:
输入:products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse"
输出:[
["mobile","moneypot","monitor"],
["mobile","moneypot","monitor"],
["mouse","mousepad"],
["mouse","mousepad"],
["mouse","mousepad"]
]
解释:按字典序排序后的产品列表是 ["mobile","moneypot","monitor","mouse","mousepad"]
输入 m 和 mo,由于所有产品的前缀都相同,所以系统返回字典序最小的三个产品 ["mobile","moneypot","monitor"]
输入 mou, mous 和 mouse 后系统都返回 ["mouse","mousepad"]
示例 2:
输入:products = ["havana"], searchWord = "havana"
输出:[["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
示例 3:
输入:products = ["bags","baggage","banner","box","cloths"], searchWord = "bags"
输出:[["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]]
示例 4:
输入:products = ["havana"], searchWord = "tatiana"
输出:[[],[],[],[],[],[],[]]
提示:
1 <= products.length <= 10001 <= Σ products[i].length <= 2 * 10^4products[i]中所有的字符都是小写英文字母。1 <= searchWord.length <= 1000searchWord中所有字符都是小写英文字母。
1166. 设计文件系统
难度中等26
你需要设计一个文件系统,你可以创建新的路径并将它们与不同的值关联。
路径的格式是一个或多个连接在一起的字符串,形式为: / ,后面跟着一个或多个小写英文字母。例如, " /leetcode" 和 "/leetcode/problems" 是有效路径,而空字符串 "" 和 "/" 不是。
实现 FileSystem 类:
bool createPath(string path, int value)创建一个新的path,并在可能的情况下关联一个value,然后返回true。如果路径已经存在或其父路径不存在,则返回false。int get(string path)返回与path关联的值,如果路径不存在则返回-1。
示例 1:
输入:
["FileSystem","create","get"]
[[],["/a",1],["/a"]]
输出:
[null,true,1]
解释:
FileSystem fileSystem = new FileSystem();
fileSystem.create("/a", 1); // 返回 true
fileSystem.get("/a"); // 返回 1
示例 2:
输入:
["FileSystem","createPath","createPath","get","createPath","get"]
[[],["/leet",1],["/leet/code",2],["/leet/code"],["/c/d",1],["/c"]]
输出:
[null,true,true,2,false,-1]
解释:
FileSystem fileSystem = new FileSystem();
fileSystem.createPath("/leet", 1); // 返回 true
fileSystem.createPath("/leet/code", 2); // 返回 true
fileSystem.get("/leet/code"); // 返回 2
fileSystem.createPath("/c/d", 1); // 返回 false 因为父路径 "/c" 不存在。
fileSystem.get("/c"); // 返回 -1 因为该路径不存在。
提示:
- 对两个函数的调用次数加起来小于等于
104 2 <= path.length <= 1001 <= value <= 109