Hash Table Exercise 1
哈希表是根据关键码的值而直接进行访问的数据结构。
242. 有效的字母异位词 & 剑指 Offer II 032. 有效的变位词
难度简单472
给定两个字符串 *s* 和 *t* ,编写一个函数来判断 *t* 是否是 *s* 的字母异位词。
注意:若 *s* 和 *t* 中每个字符出现的次数都相同,则称 *s* 和 *t* 互为字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
示例 2:
输入: s = "rat", t = "car"
输出: false
思路:
- 定义一个数组叫做record用来上记录字符串s里字符出现的次数
- 把字符映射到哈希表的索引下标上,因为字符a到字符z的ASCII是26个连续的数值,所以字符a映射为下标0,相应的字符z映射为下标25
- 那看一下如何检查字符串t中是否出现了这些字符,同样在遍历字符串t的时候,对t中出现的字符映射哈希表索引上的数值再做-1的操作
- record数组如果有的元素不为零0,说明字符串s和t一定是谁多了字符或者谁少了字符,return false。
- 最后如果record数组所有元素都为零0,说明字符串s和t是字母异位词,return true
- 时间复杂度为O(n), 空间复杂度为O(1)
代码:
- 获得字母的顺序是ord()
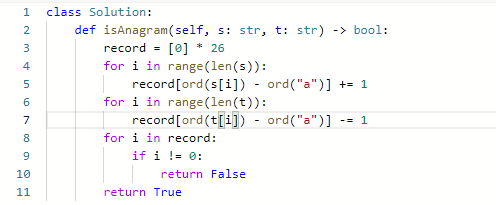

这个做法可以应对有unicode code的情况
349. 两个数组的交集
难度简单458
给定两个数组,编写一个函数来计算它们的交集。
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
思路:
- 使用数组来做哈希的题目,是因为题目都限制了数值的大小。
- 而这道题目没有限制数值的大小,就无法使用数组来做哈希表了。
- 而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
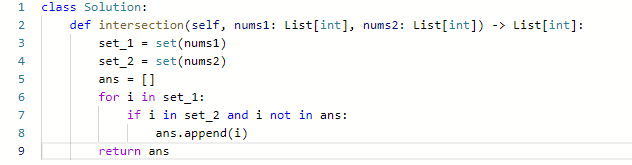
- 此时就要使用另一种结构体了,set
- 但是直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的
- 这道题就是先将两个数组变为set,再求交集后放回数组
代码:
- 可以用Python的内建功能”&“,来求不重复的交集

202. 快乐数
难度简单760
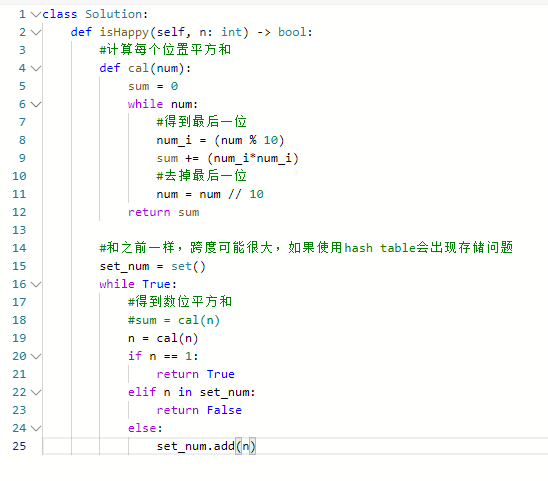
编写一个算法来判断一个数 n 是不是快乐数。
「快乐数」定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。
- 如果 可以变为 1,那么这个数就是快乐数。
如果 n 是快乐数就返回 true ;不是,则返回 false 。
示例 1:
输入:n = 19
输出:true
解释:
12 + 92 = 82
82 + 22 = 68
62 + 82 = 100
12 + 02 + 02 = 1
示例 2:
输入:n = 2
输出:false
思路:
- 题目中说了会 无限循环,那么也就是说求和的过程中,==sum会重复出现==,这对解题很重要!
- 正如:关于哈希表,你该了解这些! (opens new window)中所说==,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了==。
- 使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。
- 第 1 部分我们按照题目的要求做数位分离,求平方和。
- 第 2 部分可以使用哈希集合完成。每次生成链中的下一个数字时,我们都会检查它是否已经在哈希集合中。
- 如果它不在哈希集合中,我们应该添加它。
- 如果它在哈希集合中,这意味着我们处于一个循环中,因此应该返回 false。
代码:
- 注意去掉最后一位://10
- 获得最后一位:%10
- set的初始化:set()
- set的添加:add()
- 特别容易错的一个是写成
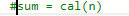 ,这样下次更新的适合还是对n计算
,这样下次更新的适合还是对n计算
1. 两数之和
难度简单14132
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
示例 2:
输入:nums = [3,2,4], target = 6
输出:[1,2]
示例 3:
输入:nums = [3,3], target = 6
输出:[0,1]
提示:
2 <= nums.length <= 104-109 <= nums[i] <= 109-109 <= target <= 109- 只会存在一个有效答案
进阶:你可以想出一个时间复杂度小于 O(n2) 的算法吗?
思路:
- 242. 有效的字母异位词 (opens new window)这用数组作为哈希表来解决哈希问题,
- 349. 两个数组的交集 (opens new window)通过set作为哈希表来解决哈希问题。
- 这道题使用Python的dict来解决哈希问题
- 使用数组和set来做哈希法的局限:
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。所以set 也不能用。
代码:
- 注意返回的是idx所以要用dict,所以存储时用val作为键,idx作为值
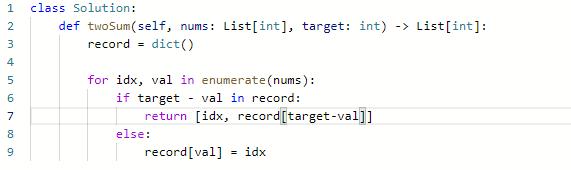
454. 四数相加 II
难度中等467
给你四个整数数组 nums1、nums2、nums3 和 nums4 ,数组长度都是 n ,请你计算有多少个元组 (i, j, k, l) 能满足:
0 <= i, j, k, l < nnums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
示例 1:
输入:nums1 = [1,2], nums2 = [-2,-1], nums3 = [-1,2], nums4 = [0,2]
输出:2
解释:
两个元组如下:
1. (0, 0, 0, 1) -> nums1[0] + nums2[0] + nums3[0] + nums4[1] = 1 + (-2) + (-1) + 2 = 0
2. (1, 1, 0, 0) -> nums1[1] + nums2[1] + nums3[0] + nums4[0] = 2 + (-1) + (-1) + 0 = 0
示例 2:
输入:nums1 = [0], nums2 = [0], nums3 = [0], nums4 = [0]
输出:1
思路:
- 首先建立一个dict,dict的key是nums1元素和nums2元素的和,value是这个和出现的次数,出现了几次,就说明有几个对于的来自nums1和nums2的组合
- 然后再遍历nums3和nums4的和,然后把这个和取反作为key,如果这个key真的存在,那么结果就加一
代码:
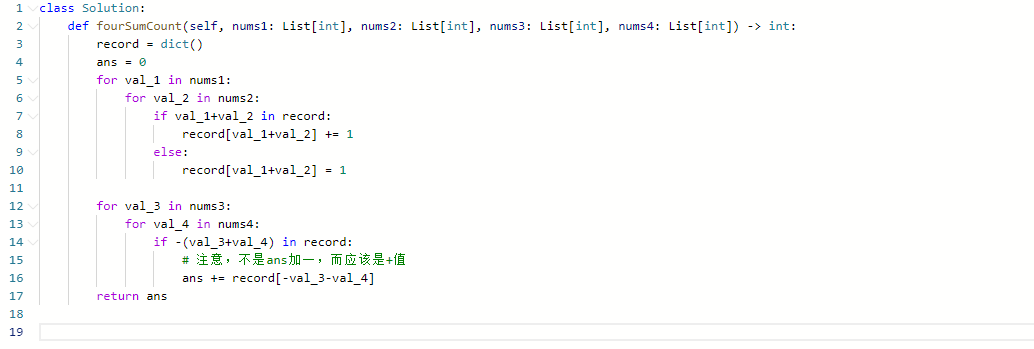
383. 赎金信
难度简单259
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
如果可以,返回 true ;否则返回 false 。
magazine 中的每个字符只能在 ransomNote 中使用一次。
示例 1:
输入:ransomNote = "a", magazine = "b"
输出:false
示例 2:
输入:ransomNote = "aa", magazine = "ab"
输出:false
示例 3:
输入:ransomNote = "aa", magazine = "aab"
输出:true
思路:
- 这道题目和242.有效的字母异位词 (opens new window)很像,242.有效的字母异位词 (opens new window)相当于求 字符串a 和 字符串b 是否可以相互组成 ,而这道题目是求 字符串a能否组成字符串b
- 因为题目所只有小写字母,那可以采用空间换取时间的哈希策略, 用一个长度为26的数组还记录magazine里字母出现的次数。
- 再用ransomNote去验证这个数组是否包含了ransomNote所需要的所有字母
- 如果使用dict他的空间损耗非常大
- 注意英文表达,一开始我会以为必须要完全一样的排序,但是他只是要字符数满足就可以了
代码:
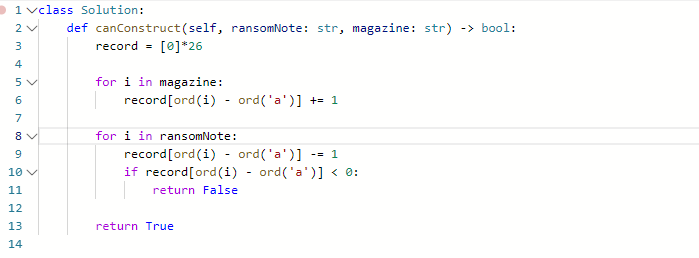
953. 验证外星语词典(verifying-an-alien-dictionary) & 剑指 Offer II 034. 外星语言是否排序
某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。
给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外星语中按字典序排列时,返回 true;否则,返回 false。
示例 1:
输入:words = [“hello”,”leetcode”], order = “hlabcdefgijkmnopqrstuvwxyz” 输出:true 解释:在该语言的字母表中,’h’ 位于 ‘l’ 之前,所以单词序列是按字典序排列的。
示例 2:
输入:words = [“word”,”world”,”row”], order = “worldabcefghijkmnpqstuvxyz” 输出:false 解释:在该语言的字母表中,’d’ 位于 ‘l’ 之后,那么 words[0] > words[1],因此单词序>列不是按字典序排列的。
示例 3:
输入:words = [“apple”,”app”], order = “abcdefghijklmnopqrstuvwxyz” 输出:false 解释:当前三个字符 “app” 匹配时,第二个字符串相对短一些,然后根据词典编纂规则 “apple” > “app”,因为 ‘l’ > ‘∅’,其中 ‘∅’ 是空白字符,定义为比任何其他字符都小(更多信息)。
思路:
- 给了外星人的顺序order,用dict来存储
- 字典序比较的时候,只有前面的字符等时才会比较后面的字符的大小。第一个示例第一个字符的比较结果就可以确定整个字符串的大小关系,不需要再考虑后面的字符。
- 相邻的word[i]逐一比较,一旦出现顺序错误,则报错
- 对于比较,我们分两类讨论:
- 两个单词长度不同,但是出现的部分都是重合的,比如apple和app。由于app比apple短,所以app必须在apple前面,即app <= apple
- 如果两个单词没到任何一个人的尾部,就已经出现不同,则检查这个是否符合order顺序吗。直到出现不符,否则为True
- 字典哈希表的实现方式:
order_index = {c: i for i, c in enumerate(order)}注意是值对应键,因为我们查找时是用字母值查找对应的顺序 - 注意要break来终止后续的比较, ==发现第一位不相等,如果符合顺序就说明整个都符合,因为他们不相等。break==,再去看。如果不符合顺序,就return False
- for else是如果for顺利完再会执行else,如果由于return 和break中断,则不会执行else
代码:
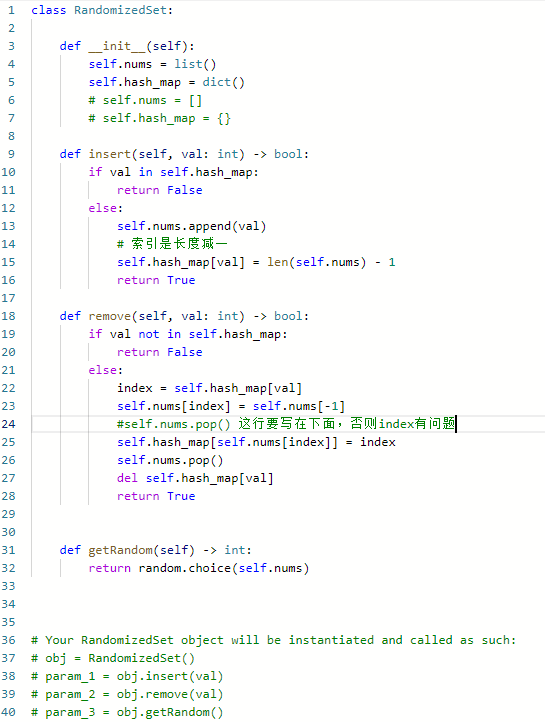
380. O(1) 时间插入、删除和获取随机元素 & 剑指 Offer II 030. 插入、删除和随机访问都是 O(1) 的容器
难度中等459
实现RandomizedSet 类:
RandomizedSet()初始化RandomizedSet对象bool insert(int val)当元素val不存在时,向集合中插入该项,并返回true;否则,返回false。bool remove(int val)当元素val存在时,从集合中移除该项,并返回true;否则,返回false。int getRandom()随机返回现有集合中的一项(测试用例保证调用此方法时集合中至少存在一个元素)。每个元素应该有 相同的概率 被返回。
你必须实现类的所有函数,并满足每个函数的 平均 时间复杂度为 O(1) 。
示例:
输入
["RandomizedSet", "insert", "remove", "insert", "getRandom", "remove", "insert", "getRandom"]
[[], [1], [2], [2], [], [1], [2], []]
输出
[null, true, false, true, 2, true, false, 2]
解释
RandomizedSet randomizedSet = new RandomizedSet();
randomizedSet.insert(1); // 向集合中插入 1 。返回 true 表示 1 被成功地插入。
randomizedSet.remove(2); // 返回 false ,表示集合中不存在 2 。
randomizedSet.insert(2); // 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。
randomizedSet.getRandom(); // getRandom 应随机返回 1 或 2 。
randomizedSet.remove(1); // 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。
randomizedSet.insert(2); // 2 已在集合中,所以返回 false 。
randomizedSet.getRandom(); // 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。
思路:
- 出现要求O(1),一般就是空间换时间,会想到hash table
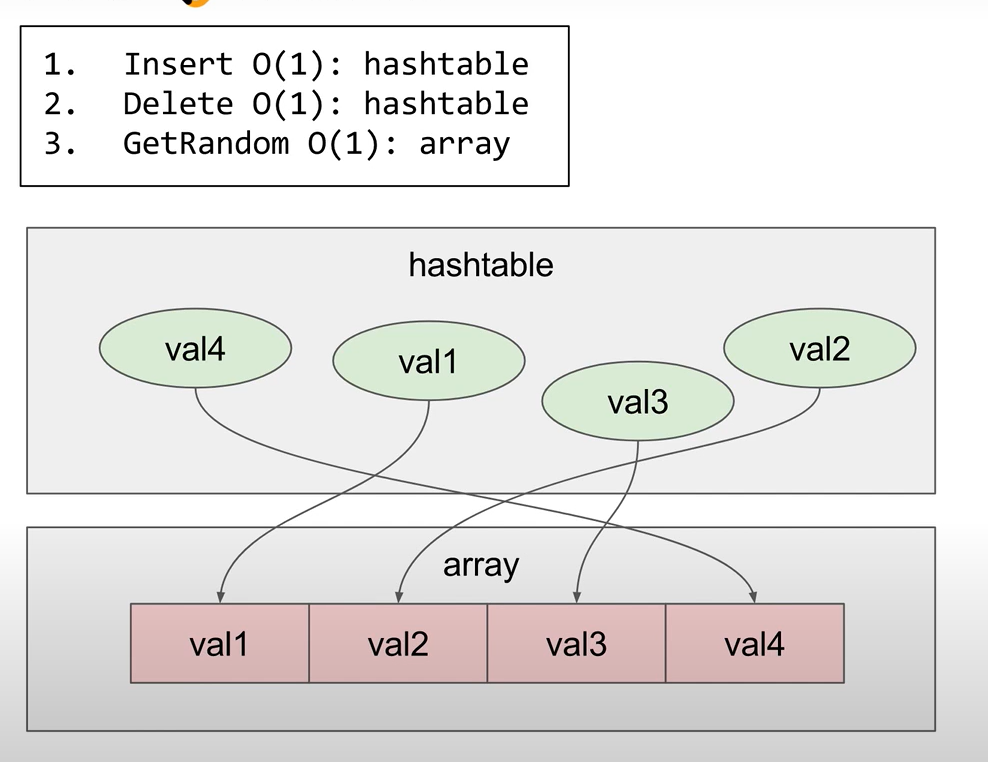
-
变长数组可以在 O(1) 的时间内完成获取随机元素操作;无不能在 O(1) 的时间内完成插入和删除操作
-
哈希表可以在 O(1) 的时间内完成插入和删除操作,但是由于无法根据下标定位到特定元素
- 对于随机的部分,使用random.choice()
-
插入操作时,首先判断 val是否在哈希表中,如果已经存在则返回 false
- 如果不存在则在变长数组的末尾添加val;
- 将 val 和下标index 存入哈希表;
- 哈希表的键(索引)是当前数字的val,值是存在数组中的index
- 返回True
-
对于删除操作,先判断 val是否在哈希表中,如果不存在则返回 false
- 在哈希表中获得val的下标index,将数组的末尾的值移动到index,将哈希表中该值的下标改为index
- 删除数组中最后一个元素
- 使用pop()
- 删除哈希表中val
- 使用del
- 返回True

删除操作的重点在于将变长数组的最后一个元素移动到待删除元素的下标处, 然后删除变长数组的最后一个元素。该操作的时间复杂度是 O(1),且可以保证在删除操作之后变长数组中的所有元素的下标都连续,方便插入操作和获取随机元素操作。
代码:
49. 字母异位词分组 & 剑指 Offer II 033. 变位词组
难度中等1092
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
示例 2:
输入: strs = [""]
输出: [[""]]
示例 3:
输入: strs = ["a"]
输出: [["a"]]
思路:
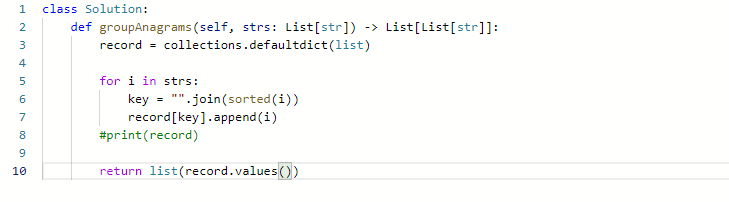
- Python使用key访问字典,如果key不存在,会报错
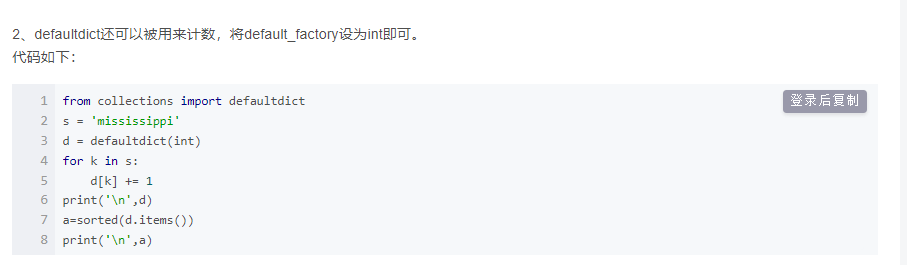
- 可以用collections.defaultdict(), defaultdict是Python内建字典类(dict)的一个子类,它重写了方法_missing_(key),
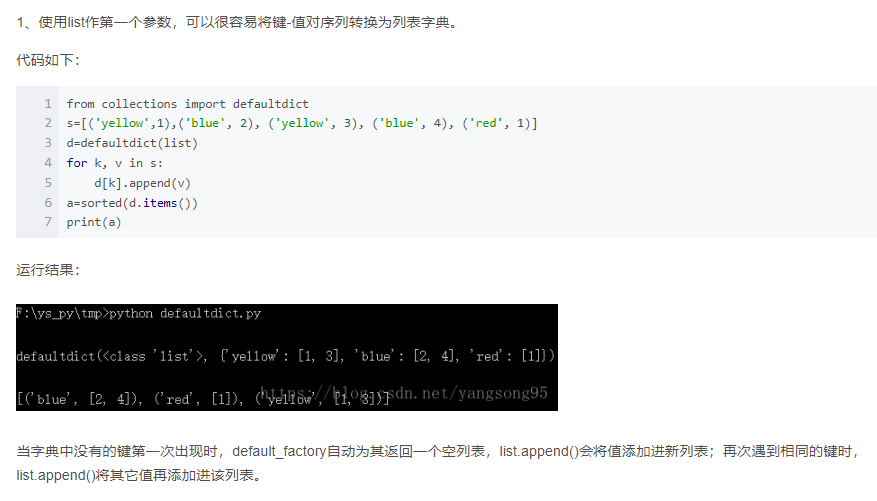
方法一是对两个字符串分别进行排序之后得到的字符串进行比较,然后用排序的结果作为key,之前的字符串作为value
-
初始化用collections.defaultdict(list)
- 这里的list决定存储形式
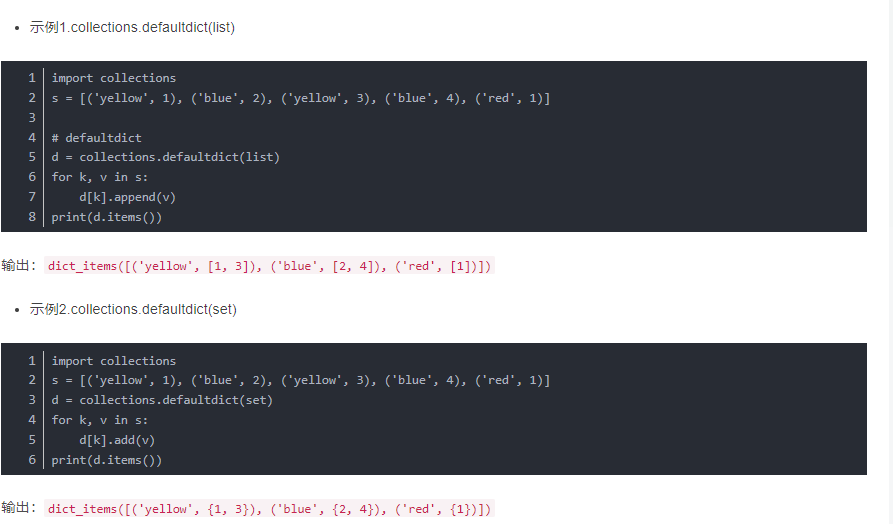
-
排序用sorted()
-
”“.join是用来拼接字符串,因为sorted的结果是多个单一的字符,必须连起来
-
set添加元素是用add(), 这里dict是用append
-
返回的只需要是value,不需要排好的key。所以就是record.values();==注意括号!==
- 它出来的是许多个list,这是由于初始化时collections.defaultdict(list)
- 但是要求是外面再有个框,所以是list(record.values())

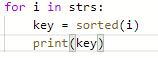
代码:
方法二是对于每个字符串进行字母计数,但是不明白为什么一定要用set
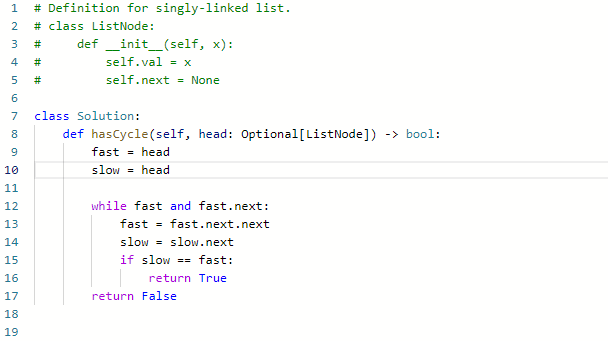
141. 环形链表
难度简单1453
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:

输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
提示:
- 链表中节点的数目范围是
[0, 104] -105 <= Node.val <= 105pos为-1或者链表中的一个 有效索引 。
进阶:你能用 O(1)(即,常量)内存解决此问题吗?
思路:
- 这道题使用哈希表虽然好想,但是空间复杂度为O(N), 如果我们希望时间复杂度是O(1),需要使用双指针
- 回忆一下数组和set的局限:
- 数组的大小是受限制的,而且如果元素很少,而哈希值太大会造成内存空间的浪费。
- set是一个集合,里面放的元素只能是一个key,而两数之和这道题目,不仅要判断y是否存在而且还要记录y的下标位置,因为要返回x 和 y的下标。
- 只有又要索引又要值的才要dict
- 这道题只需要记录是不是经过某个点。注意必须存储head,而不是值,值会重复
代码:
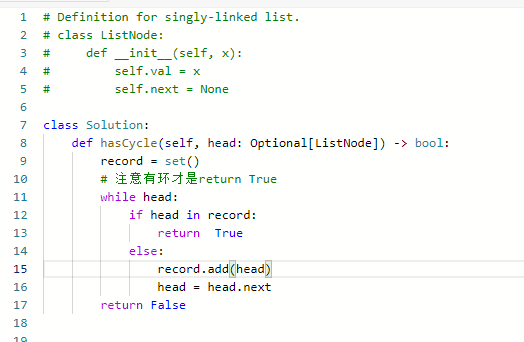
时间和空间复杂度O(N)
使用双指针则是利用快慢指针,如果快指针一次动两格,慢指针一次动一个,理论上慢指针永远追不上快指针,除非存在环。
- 总之如果真的存在环,我们就让他跑就行了,因为一定会赶上。
- 如果不存在环,那么就是一定存在结尾,它的next是None。但是考虑到一次走两格的fast,我们判断依据是fast和fast.next
146. LRU 缓存 &剑指 Offer II 031. 最近最少使用缓存
难度中等2095
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105次get和put
思路:
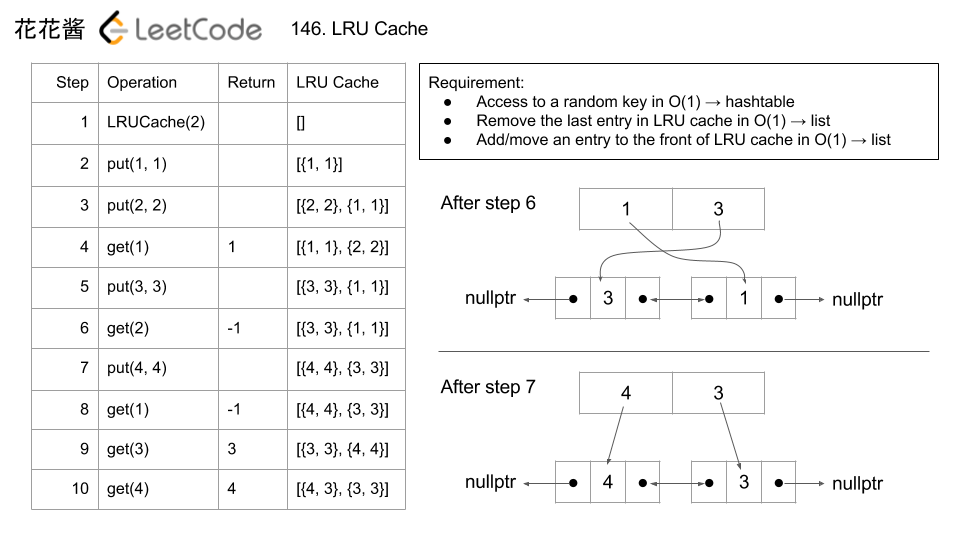
- 注意第四步会把{1,1}放在前面,说明最近使用
- 因为要在O(1)内访问随机的key,所以一定是hash table
- 删除最尾端,O(1)
- 移动元素到最左端,O(1)
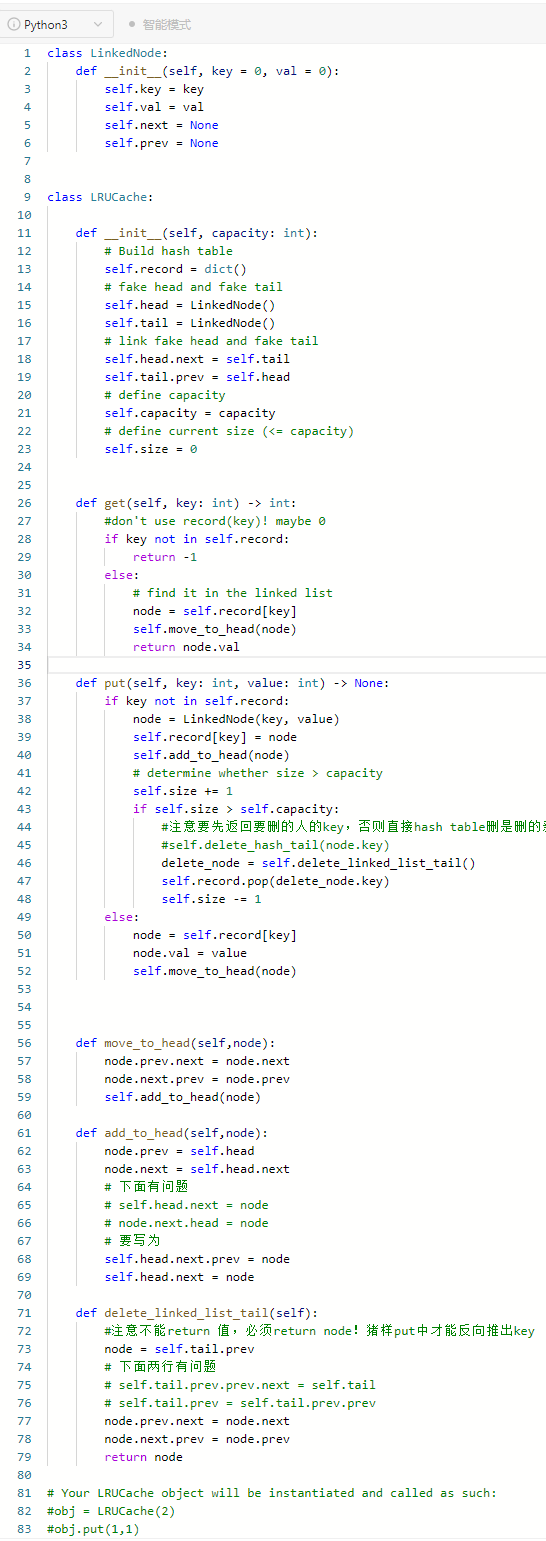
- 支持上述两个O(1)操纵的就是双向链表,而hash table用于把键映射到链表的位置
- 注意双向链表需要伪头部和伪尾部
- 对于get(key)
- 如果在hash table找到了key,那就说明链表也有。用hash table存的node,并将它移动到链表的头部,返回存储的值
- 如果没找到,返回-1
- 对于put(key)
- 如果hash table找到了key,那就和get一样,那就说明链表也有。用hash table存的node,并将它移动到链表的头部,再修改其中的值
- 如果hash table没找到key,就用key和val新建一个链表node,然后将链表的头部指向该节点。再将key放入hash table. Then we need to determine whether 超出容量,如果超出,删去双向链表的节点和哈希表中的key
代码:
- 先抽象出删除和移动的功能,再通过作图来进行链表操作代码编写。
Time: O(1)
Space: O(1)
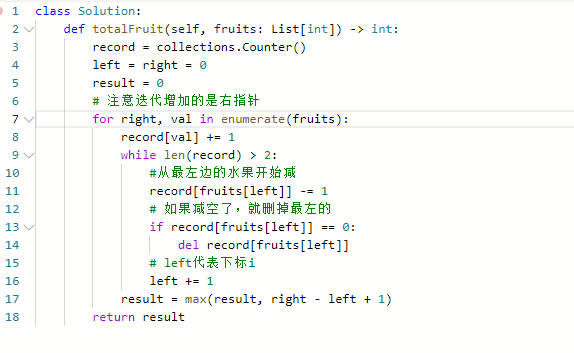
904. 水果成篮
难度中等193
你正在探访一家农场,农场从左到右种植了一排果树。这些树用一个整数数组 fruits 表示,其中 fruits[i] 是第 i 棵树上的水果 种类 。
你想要尽可能多地收集水果。然而,农场的主人设定了一些严格的规矩,你必须按照要求采摘水果:
- 你只有 两个 篮子,并且每个篮子只能装 单一类型 的水果。每个篮子能够装的水果总量没有限制。
- 你可以选择任意一棵树开始采摘,你必须从 每棵 树(包括开始采摘的树)上 恰好摘一个水果 。采摘的水果应当符合篮子中的水果类型。每采摘一次,你将会向右移动到下一棵树,并继续采摘。
- 一旦你走到某棵树前,但水果不符合篮子的水果类型,那么就必须停止采摘。
给你一个整数数组 fruits ,返回你可以收集的水果的 最大 数目。
示例 1:
输入:fruits = [1,2,1]
输出:3
解释:可以采摘全部 3 棵树。
示例 2:
输入:fruits = [0,1,2,2]
输出:3
解释:可以采摘 [1,2,2] 这三棵树。
如果从第一棵树开始采摘,则只能采摘 [0,1] 这两棵树。
示例 3:
输入:fruits = [1,2,3,2,2]
输出:4
解释:可以采摘 [2,3,2,2] 这四棵树。
如果从第一棵树开始采摘,则只能采摘 [1,2] 这两棵树。
示例 4:
输入:fruits = [3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:可以采摘 [1,2,1,1,2] 这五棵树。
提示:
1 <= fruits.length <= 1050 <= fruits[i] < fruits.length
通过次数41,645
提交次数94,725
思路:
-
这道题的做法是滑动窗口,之后可以多做些这种类型的题目
-
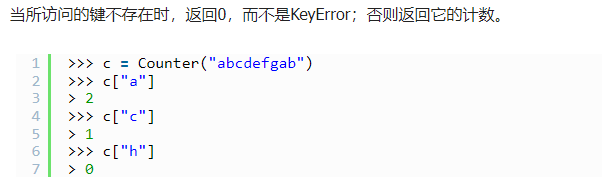
使用collections.Counter()来进行计数
-
关键点是只能装俩种水果,而且从哪里开始摘了就必须一直摘下去,除非出现第三种水果
-
假设是从下标i到下标j满足上述的要求,对于指定的j,我们希望i越小越好
-
使用哈希表,走滑动窗口
- 创建一个空的哈希表,并设置左指针为0
- 然后遍历数组,将出现的次数记录在哈希表中
- 当哈希表的长度大于2时,右移左指针,在过程中删除哈希表中的对应内容,直至长度为2停止
- 循环上述两步,并持续计算满足要求后的最大长度即可。
代码:
时间,空间复杂度都是O(N), N是len(fruits)
2013. 检测正方形
难度中等106
给你一个在 X-Y 平面上的点构成的数据流。设计一个满足下述要求的算法:
- 添加 一个在数据流中的新点到某个数据结构中。可以添加 重复 的点,并会视作不同的点进行处理。
- 给你一个查询点,请你从数据结构中选出三个点,使这三个点和查询点一同构成一个 面积为正 的 轴对齐正方形 ,统计 满足该要求的方案数目。
轴对齐正方形 是一个正方形,除四条边长度相同外,还满足每条边都与 x-轴 或 y-轴 平行或垂直。
实现 DetectSquares 类:
DetectSquares()使用空数据结构初始化对象void add(int[] point)向数据结构添加一个新的点point = [x, y]int count(int[] point)统计按上述方式与点point = [x, y]共同构造 轴对齐正方形 的方案数。
示例:
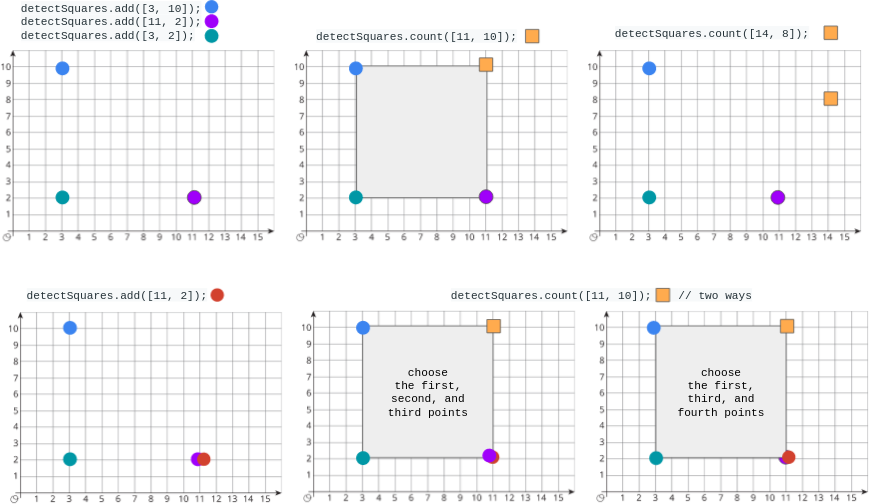
输入:
["DetectSquares", "add", "add", "add", "count", "count", "add", "count"]
[[], [[3, 10]], [[11, 2]], [[3, 2]], [[11, 10]], [[14, 8]], [[11, 2]], [[11, 10]]]
输出:
[null, null, null, null, 1, 0, null, 2]
解释:
DetectSquares detectSquares = new DetectSquares();
detectSquares.add([3, 10]);
detectSquares.add([11, 2]);
detectSquares.add([3, 2]);
detectSquares.count([11, 10]); // 返回 1 。你可以选择:
// - 第一个,第二个,和第三个点
detectSquares.count([14, 8]); // 返回 0 。查询点无法与数据结构中的这些点构成正方形。
detectSquares.add([11, 2]); // 允许添加重复的点。
detectSquares.count([11, 10]); // 返回 2 。你可以选择:
// - 第一个,第二个,和第三个点
// - 第一个,第三个,和第四个点
提示:
point.length == 20 <= x, y <= 1000- 调用
add和count的 总次数 最多为5000
思路:
代码:
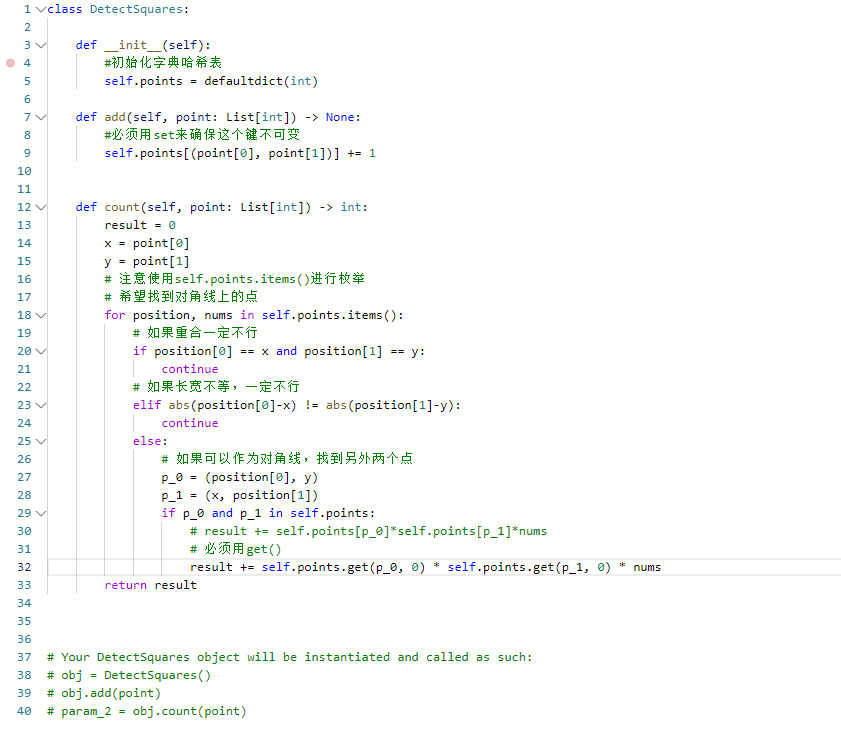
注意p_0和p_1可能不存在,所以给默认值0!